微軟 Azure AI 語音服務推出虛擬人形象 支持文本轉視頻功能
2024-08-23 09:33:22 |
棠糖 |
1051
8月23日,微軟宣布全面推出其 Azure AI 語音服務中的新功能——Text to Speech Avatar。這項創新技術使開發者能夠將簡單的文本轉換為自然說話的人類視頻,為用戶提供個性化的虛擬人形象。該功能的引入標志著微軟在生成式 AI 語音和視頻技術方面的又一重要進展。
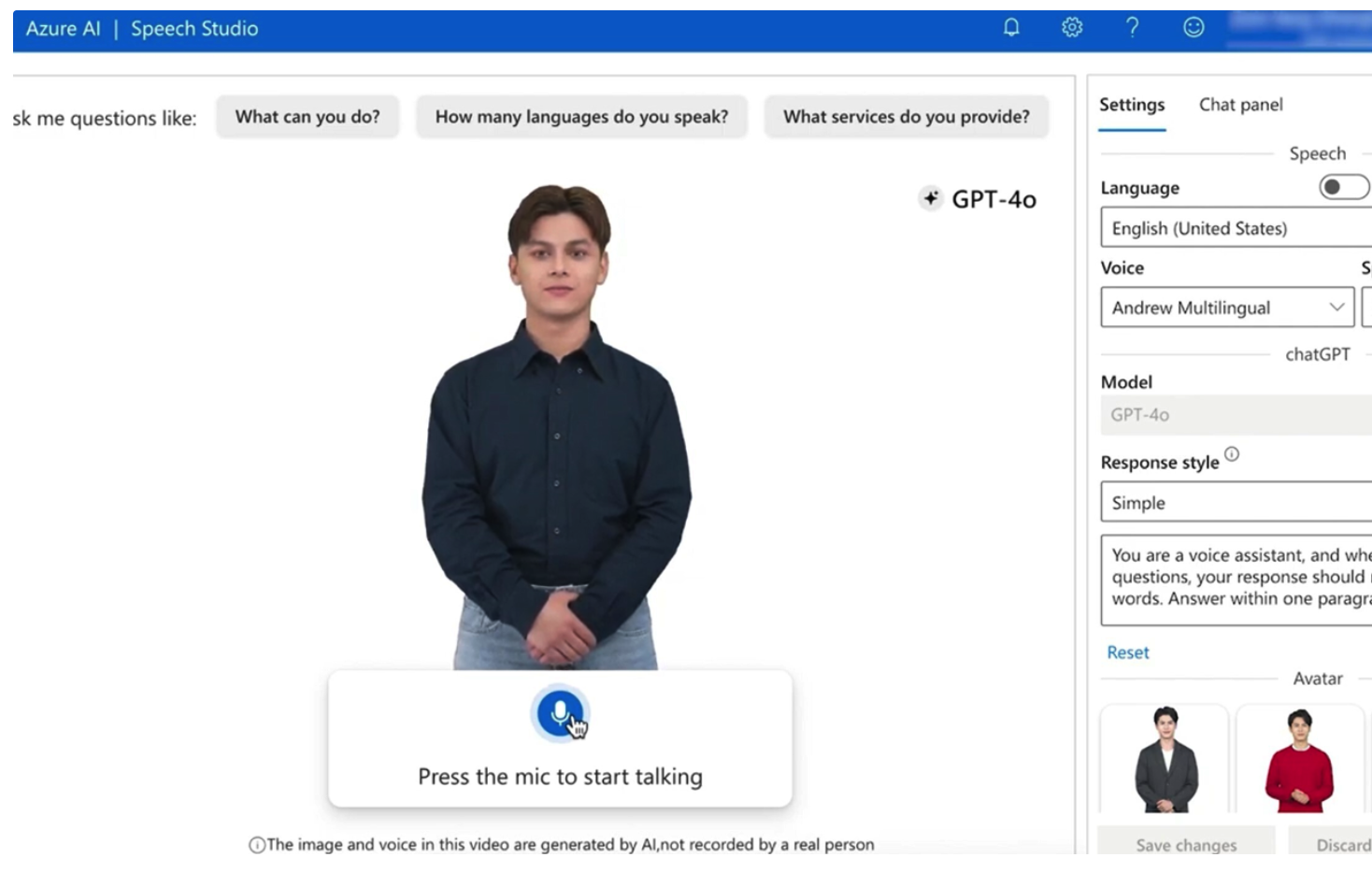
Text to Speech Avatar 功能專注于為開發者和企業提供創建虛擬人視頻的能力,其視頻輸出達到 1920 x 1080 的高清分辨率,每秒 25 幀。開發者可以使用 Azure AI 文本轉語音技術將文本內容轉化為逼真且自然的說話視頻。這項功能特別適用于需要互動視頻內容的應用場景,如客戶服務、在線教育和營銷等。
Text to Speech Avatar 的關鍵特點包括:
1. 自然語音生成:基于 Azure AI 文本轉語音技術,生成自然且真實的人類說話視頻,使虛擬人形象更具吸引力和可信度。
2. 多樣化的人物預設: 開發者可以選擇不同的人物預設形象,以滿足不同場景和用戶的需求。
3. 批量和實時合成:支持通過批量合成 API 異步或實時合成文本到語音人像視頻,提高開發和內容創作的效率。
4. 內容創建工具:在 Speech Studio 中提供的內容創建工具使用戶無需編碼即可輕松創建視頻內容,降低了技術門檻。
5. 實時對話功能:Speech Studio 還提供了實時聊天頭像工具,支持實時人像對話,增強了用戶互動體驗。
微軟表示,Text to Speech Avatar 功能將根據視頻輸出的時長按秒收費,確保企業可以根據實際使用情況靈活控制成本。目前,這項服務已在東南亞、北歐、西歐、瑞典中部、美國中南部和美國西部地區上線,未來有望在更多地區推廣。
特別提醒:本網信息來自于互聯網,目的在于傳遞更多信息,并不代表本網贊同其觀點。其原創性以及文中陳述文字和內容未經本站證實,對本文以及其中全部或者部分內容、文字、圖片等內容的真實性、完整性、及時性本站不作任何保證或承諾,請自行核實相關內容。本站不承擔此類作品侵權行為的直接責任及連帶責任。如若本網有任何內容侵犯您的權益,請及時發送相關信息至bireading@163.com,本站將會在48小時內處理完畢。